- October 12, 2021
- Posted by: EARSC
- Categories: European EO Industry, Members News

By Kristof Van Tricht 19.07.2021
ESA WorldCereal’s challenging task is to build an open-source classification system for seasonal crop mapping at the global scale. For every 10 m X 10 m pixel on Earth we need to be able to tell if this pixel is being cultivated or not and if yes, if it was irrigated and if in one of the main agricultural seasons wheat or maize was grown on that pixel.
Given the amount of potential approaches to tackle these tasks, a thorough benchmarking exercise was paramount. This exercise should provide objective arguments allowing us to define what works and what doesn’t and which ultimately should lead to what we believe is the best tradeoff between a scientifically sound yet technically feasible WorldCereal classification module. Here’s what we found.
MATCHING OUR NEEDS WITH THE AVAILABLE APPROACHES
If you are familiar with classification tasks based on remote sensing data, you for sure know how many different approaches are described in scientific literature. Some approaches like robust random forest classifiers have been around for a few decades, while others such as deep convolutional and recurrent neural networks have only come around more recently. And this only covers the classification algorithm itself, while many other choices need to be made as well. It was therefore important to define some specific questions that needed an answer first, in order to be able to develop a robust WorldCereal classification system later on. The most important ones are:
- Do we work with pixel-based or patch-based classifiers?
- Do we compute expert-derived input features or do we directly feed the original time series to the classifiers?
- Are we pursuing one global model or many regional models?
- How detailed can our classification nomenclature be without jeopardizing accuracy?
The table below outlines the algorithms that we tested, ranging from pixel-based random forest classifiers to patch-based convolutional-recurrent neural network.

Classification algorithms that were tested in the WorldCereal benchmarking exercise
CROP CALENDARS, AGRO-ECOLOGICAL ZONES AND BINARY CLASSIFIERS
Before benchmarking could start, some prerequisites were needed. The seasonal nature of the WorldCereal products requires a careful assessment of global crop calendars for wheat and maize. A major task has been the creation of such global pixel-based crop calendars covering all possible wheat and maize seasons, and combining the results in grouped agro-ecological zones (see figures below), thereby leveraging as much as possible existing sources of information, such as GEOGLAM Crop Monitor, FAO crop calendars and JRC-ASAP. Based on this information, the WorldCereal system exactly knows when to process which area to generate end-of-season crop type maps for our crops of interest.
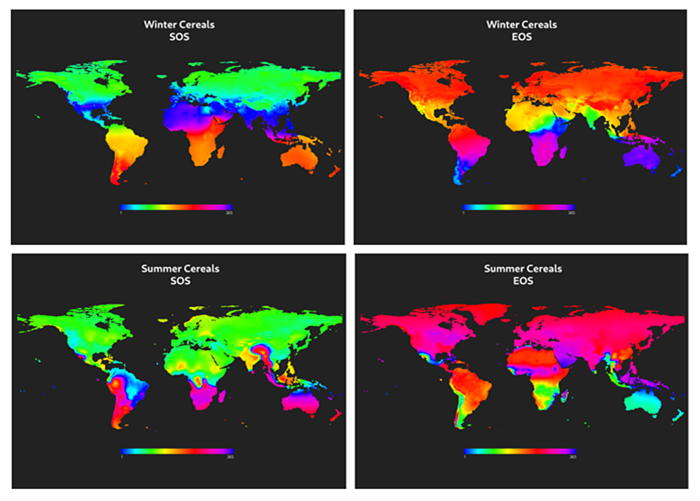
Global pixel-based crop calendars for winter and summer cereals (SOS = start of season; EOS = end of season)
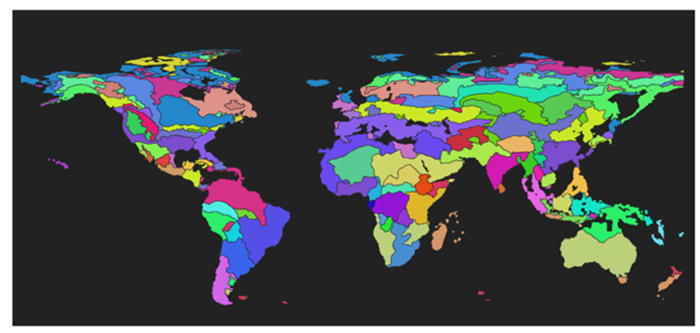
Agro-ecological zone groups, where grouping is based among others on the similarity of wheat and maize crop calendars
Next to the concepts of crop calendars and agro-ecological zones, we also decided to exclusively focus on binary classifiers in a hierarchical context. This means that the algorithms are trained to detect one class against all others. This ensures the algorithms can focus well on one particular task and avoids them being susceptible to complex classification nomenclatures that need to reflect the highly diverse global agricultural landscape.
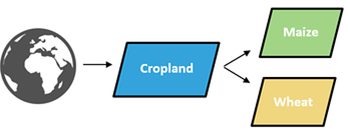
The hierarchical nature of the WorldCereal classifiers
BENCHMARKING CRITERIA
In order to come up with the best possible approach to generate the WorldCereal products at global scale, we need objective criteria to compare different algorithms. These criteria can be organized in three general categories:
- Quality-related (e.g. how accurate are the results?)
- Performance-related (e.g. what computational resources are needed?)
- Requirements-related (e.g. how much and what kind of training data is required?)
A careful tradeoff needs to be made, as for example the theoretically ‘best’ algorithm might require an amount of training data that is not everywhere available. While assessing the above criteria, we keep constant track of robustness and transferability of the algorithms because only generalizable workflows will be capable of providing consistent results at the global scale, thereby mitigating the numerous blind spots where no training data is available.
REFERENCE DATA & INPUTS
WorldCereal’s reference data repository contains a growing collection of labeled points, polygons and maps, all derived from existing data sources yet harmonized to one common legend. This reference database forms an integral part of the WorldCereal system and will be opened up for exploitation and contributions from third parties.
The benchmarking results described here were conducted on > 100,000 reference samples. For each sample, a spatio-temporal input datastack of 640 m X 640 m covering 1,5 years of input data was extracted and stored for Sentinel-1 backscatter data, Sentinel-2 L2A reflectance values and ancillary data such as AgERA5 meteo inputs and the Copernicus 30 m DEM.
PIXEL-BASED LSTM ON INPUT TIME SERIES
Nowadays convolutional neural networks working on input patches taking into account spatial context seem to take the lead in scientific literature related to classification. According to our findings, however, there’s still quite some adverse effects of these kinds of algorithms especially in regions with few and only point-based training data. While the validation score was similar for both pixel-based as well as patch-based algorithms (F1 ~0.9 for cropland), large-scale tests clearly showed visual artefacts in some regions when using patch-based approaches. Moreover, pixel-based classifiers seemed to be better capable of capturing small borders between parcels which easily get smeared out in patch-based convolutional nets (see figure below). Our default approach is therefore to work on individual pixels, focusing on the rich temporal dimension. The modular nature of the system however allows us to switch to the convolutional architecture whenever we want, for example in the European context where LPIS datasets led to excellent results using convolutional nets.

Comparison of patch-based versus pixel-based neural networks for annual cropland detection. The arrows point to parcel borders being more correctly identified in the pixel-based approach.
Interestingly, we also found in general a slight advantage of using a LSTM network on input time series over the expert computation of derived input features followed by a random forest algorithm. This suggests that for a global approach – provided that sufficient amount of reference data are available – a deep neural network is able to find some important features in the temporal domain that our expert-derived manual feature computation might have overlooked.
GLOBALLY TRAINED, REGIONALLY FINETUNED
The grouping of agro-ecological zones according to their crop calendars led to a significant reduction of regions without any useful reference data. However, still many regions with limited to no data remained. This introduces a difficult challenge: training one globally applicable model would lead to too many compromises. Training many regional models on the other hand leaves many agro-ecological zones without a model due to lack of reference data and it also could lead to artefacts at the zone borders.
We decided to go for the best of two worlds and setup a hierarchical model approach. We train a global base model on all available reference data and progressively finetune the model in regional zones if sufficient reference data is available. This leaves us with at least a base model that can be applied anywhere, while having potentially locally finetuned models that inherit from the base model but are better adapted to local conditions. Another advantage of this approach is that the regional finetuning needs much less training data, as lower-level features have already been learned in the global base model which could benefit from all reference data.
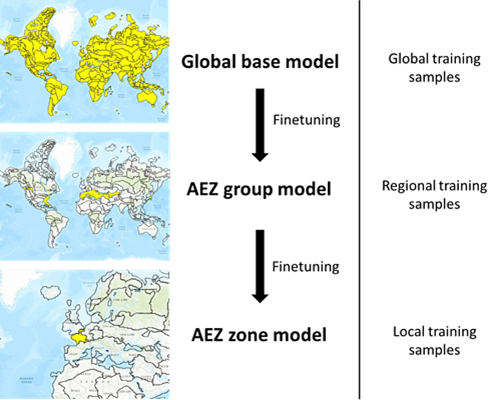
Hierarchical model approach with one global base model and several locally finetuned AEZ models.
CROP TYPE DETECTORS
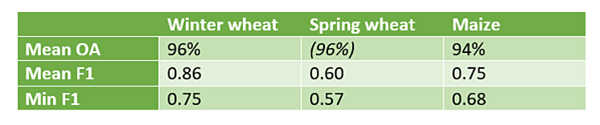
With wheat and maize being the focus crops during the WorldCereal project, we benchmarked the ability to train wheat and maize detectors. For maize, up to two seasons can take place but we did not find the need to train season-specific maize detectors. One generic maize detector can be applied to any potential maize season and we found a mean F1 score over all AEZ of 0.75.
The situation is very different for wheat. Depending on the seasonality in a region, either winter wheat, spring wheat or both can be grown. Especially aided by the concept of growing degree days which we use to normalize the input time series, winter cereals can more easily be distinguished from summer cereals. Hence we found that a generic wheat detector for both winter and summer seasons performed significantly worse than season-specific wheat detectors.
Furthermore, we benchmarked the ability to distinguish wheat from barley and rye. While it is often suggested that from a remote sensing perspective (and even in the field) these crops are hard to separate, we did find to our surprise that this was in fact possible to a reasonable degree. A combined winter cereals detector (wheat, barley and rye) for example reached a F1 score of 0.87, while a focused winter wheat detector still reached a F1 of 0.86. A large-scale validation is however planned to verify whether these findings hold or that they are attributed to some degree of inevitable overfitting. The results for the current spring wheat detector are somewhat inconclusive due to the low amount of reference data that is currently present in our data repository.

CONCLUSIONS
The global nature of the WorldCereal products revealed some interesting benchmarking results that were not always fully in line with the most recent scientific literature. We argue that the concepts of many excellent publications are not always sufficiently developed yet to be upscaled from a specialized study to an operational global mapping approach. We therefore need to make smart and well-informed design and algorithm choices to maximize our chances of success.
As usual, no one size fits all. Compromises need to be made, careful tradeoffs need to be chosen. But thanks to the rigorous benchmarking experiments that we carried out, we were able to settle down on quite a few long-standing crop mapping questions. Thanks to the modular nature of the WorldCereal system, all currently tested methods but also any future methods can be easily plugged in by the user.
And best of all? All our algorithms and methods are going to be open-sourced! We hope that this will stimulate the community to build upon our findings, and further improve our ability to map crops at a global scale. Meanwhile we’re gradually moving towards the global demonstration, where we’ll actually put our algorithms to work and generate global cropland, wheat and maize maps. Stay tuned!
